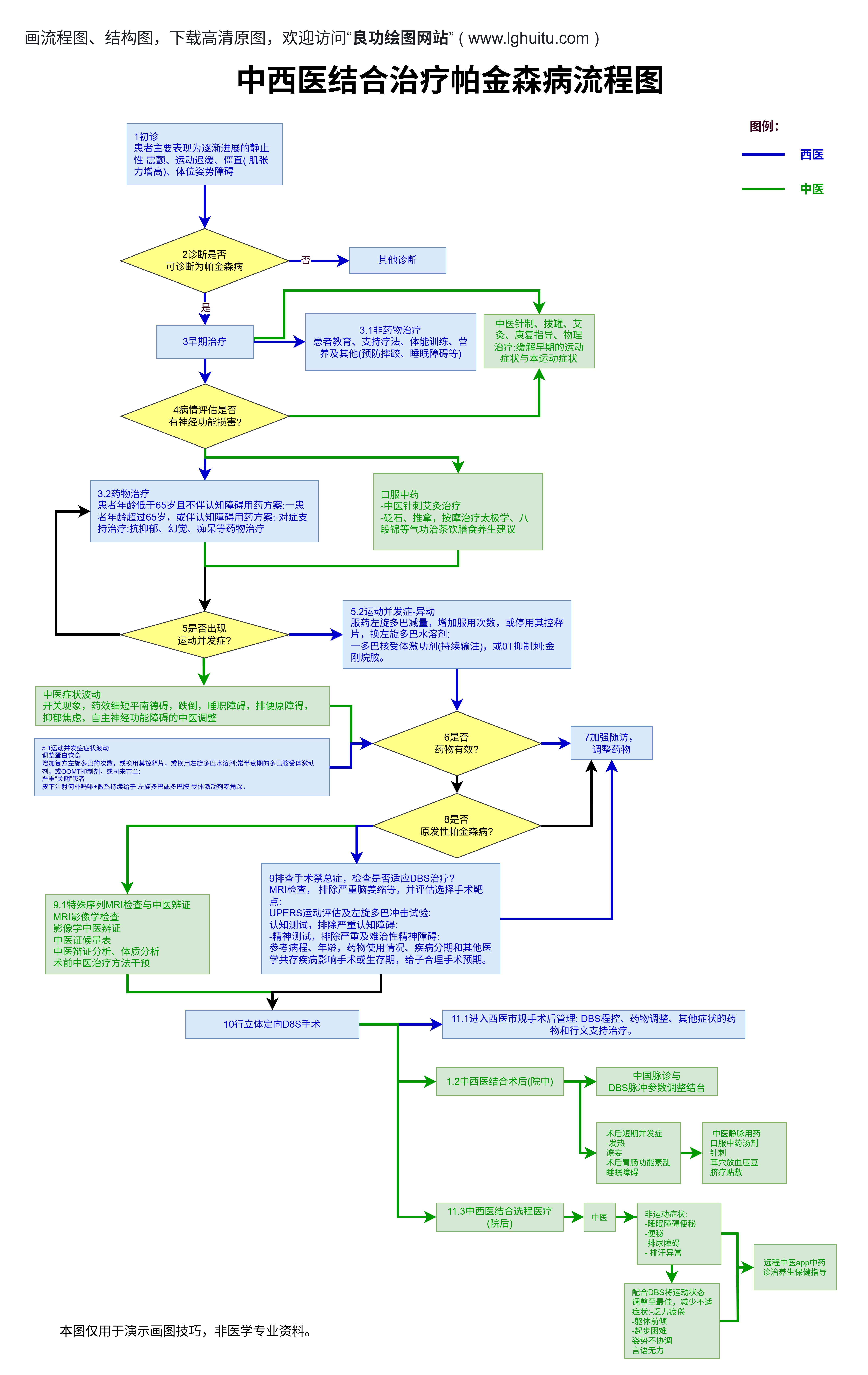
在数据科学的潮汐中,XGBoost像一艘可靠的船,但它的引擎却是由许多参数和步骤组成的错综结构。没有清晰的路线图,往往会在中途走偏,导致模型的性能和稳定性不可控。把这套复杂的流程转换成一张清晰的流程图,不仅能让团队成员对每一步的目的有共识,还可以把技术语言变成业务语言,帮助非技术同事理解模型的价值。
这就是“流程图XGBoost”的初衷:以可视化的方式,将数据进入、特征加工、模型训练、评估与上线,串成一条可追踪的线。它不是要替代代码,而是把思路变成可分享、可检查、可改进的共同语言。
一个完整的XGBoost流程图,通常从“数据准备”开始。第一节点是数据输入:你需要明确源系统、字段含义、缺失值策略、类别特征的处理方式(如是否进行目标编码、是否采用独热编码或嵌入式编码)。紧随其后的是“数据清洗与特征工程”分支:处理异常值、统一时间尺度、构造交互特征、进行分桶或分箱、计算统计派生特征。
然后进入“数据划分与验证”的阶段:设定训练集、验证集、测试集的切分策略,决定是否采用交叉验证、时间序列数据的滚动窗口等。每一个阶段都可以在流程图中用一个矩形框表示,旁边附上关键参数与输出结果,如缺失值比例、特征数量、基线模型性能等,确保每个参与人都能快速对齐。
接下来是“模型训练与迭代”的核心。XGBoost的训练过程涉及若干超参数:nestimators、learningrate、maxdepth、subsample、colsamplebytree、minchildweight等。将这些参数放入流程图中的“训练节点”,并用箭头指向“评估节点”。
评估通常包含多种指标,如AUC、LogLoss、F1等,以及对训练与验证集之间差异的对比。若设置了早停(earlystopping),流程图应明确显示:在连续若干轮没有提升时停止,并将最佳模型的性能映射到“模型选择”分支。此时,流程图不仅是操作手册,也是对尝试空间的可视化约束:哪些方向已经探索,哪些方向还可以尝试,哪些参数组合已经被排除。
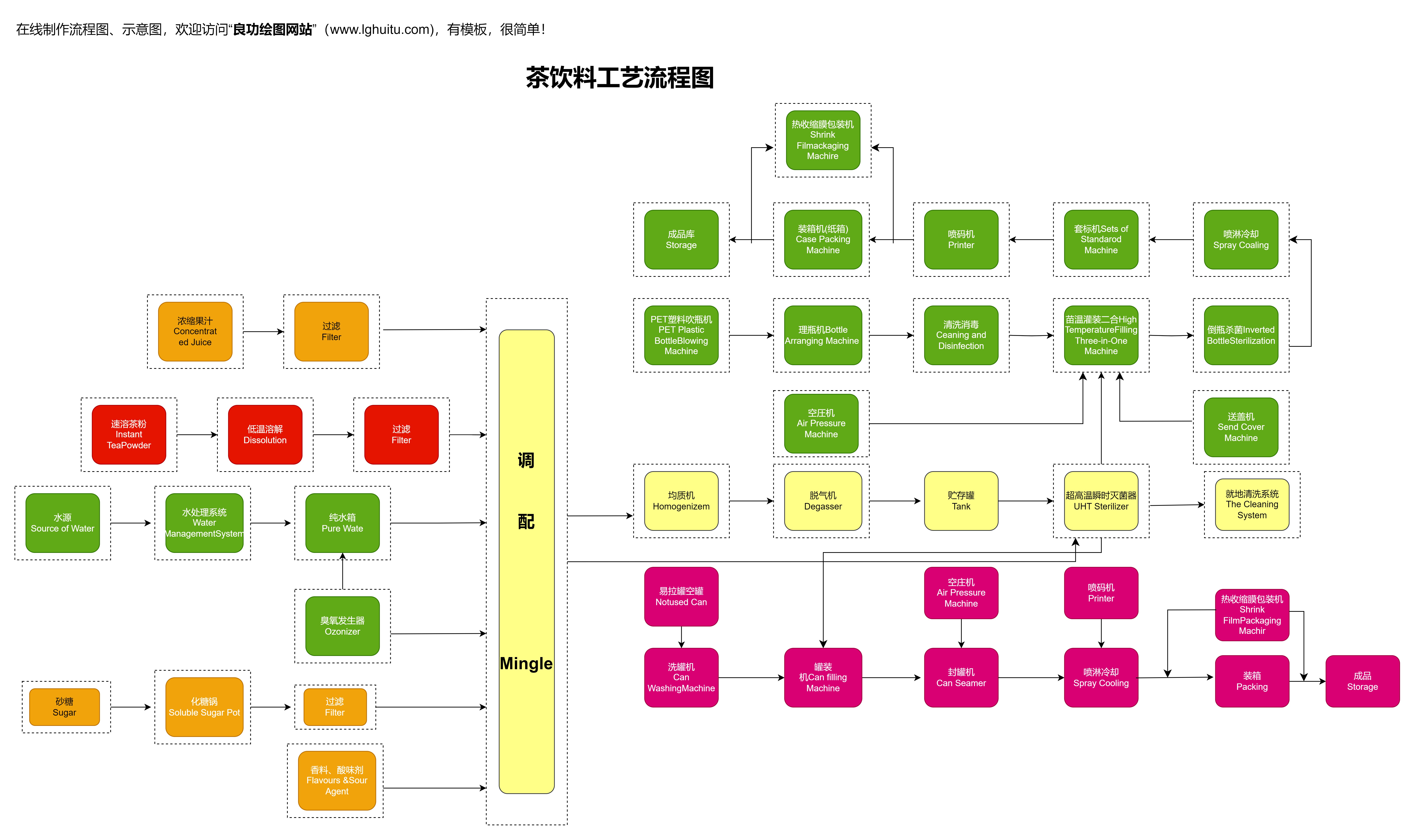
“模型解释与可解释性”是不可忽视的一环。流程图可以把特征重要性排序、SHAP值分析等步骤放在一个独立的分支,显示哪些特征对预测结果影响最大、在不同分组上的表现如何。这一点对业务团队和监管要求都至关重要。最后的分支是“部署前检查与上线”,包括模型序列化、推理环境的一致性、输入输出格式的对齐、监控指标的设定、以及回滚策略的规定。
整个流程图由头到尾连成一个闭环:数据流、模型训练、评估、解释、上线、监控、反馈,形成一个可追踪、可复现的工作流。
为什么要用流程图来驱动XGBoost?因为它把抽象转为可感知的现实。它让团队成员在屏幕上看到“这一步做了什么、为什么这么做、下一步会发生什么”,从而降低沟通成本,缩短从数据到决策的距离。对于初学者,流程图提供了一个落地的路径图,帮助他们从数据清洗到模型调优逐步深入;对于资深从业者,流程图则是一层监督与迭代的护栏,确保复杂的模型开发过程依然可控、可审计。
更重要的是,流程图促成了跨职能协作:数据工程师、数据科学家、业务分析师、产品经理可以在同一个可视化版本上对齐目标、讨论指标、评估风险,从而减少因语言不对等而带来的误解。
在实际操作中,你并不需要从零开始就画出完美的流程图。可以先从“基线版”入手:列出关键阶段和输出物,添加简单的判断条件,如“缺失值是否已处理”、“数据是否分层抽样”、“是否启用早停”等。随着模型迭代的深入,逐步丰富每个节点的内容:记录具体的参数设置、数据维度、模型训练时的资源消耗、评估结果的置信区间、重要特征的列表及其变化趋势。
最终,当你和团队熟练掌握这张流程图时,它就不仅是一张图,而是一套自解释的工作法:你知道在任何一个环节,应该观察什么、应该问哪些问题、应该如何记录与回顾,乃至如何将这份可视化的蓝图转化为标准化的SOP,帮助公司在不同项目之间快速复用成功经验。流程图XGBoost,从理解到共识,再到落地,正在以透明、可追踪的方式改变团队协作的节奏与成效。
从可解释到商业化|用流程图驱动XGBoost全生命周期
把“流程图XGBoost”推到更高层次,我们要把可解释性与治理放在同等高度,让模型从研发阶段走向生产线时,仍然拥有清晰的路径与可证伪的证据。可解释性并非一项可选的附属能力,而是对业务信任、法规合规、运营稳定性的直接贡献。流程图在这方面的价值,体现在三个层面:可追溯性、可沟通性、可操作性。
可追溯性指的是每一次特征工程、每一次超参数调整、每一次模型评估的结果都被记录在案,形成一个版本历史。可沟通性意味着无论团队成员的背景如何,他们都能在同一个图谱上理解模型的前因后果、预测逻辑和风险边界。可操作性则体现在将模型治理嵌入到日常工作流:变更申请、审查、上线、监控、回滚等环节都能从流程图中读取、执行和追踪。
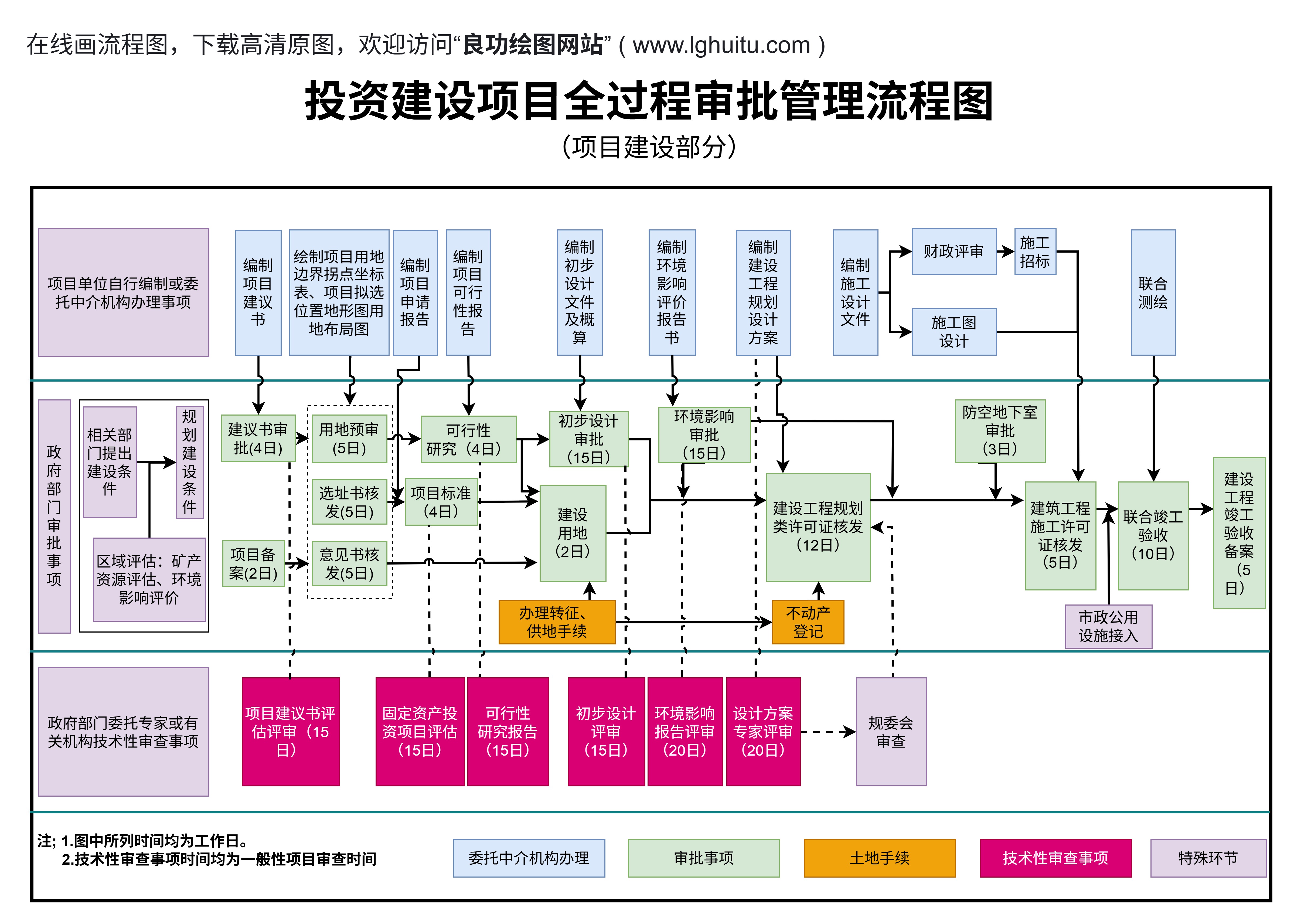
以流程图驱动XGBoost的全生命周期,可以将工作流程拆解为若干可管理的模块,每个模块对应一个或多个可交付物。首先是“需求与设计”,在流程图中明确业务目标、数据范围、合规约束、上线时间点。紧接着是“数据治理与特征治理”,将数据质量指标、数据血统、特征生成规则、审计日志等要素可视化嵌入。
第三步是“工程化训练与验证”,把训练任务、持续集成/持续交付(CI/CD)流程、模型评审、性能基线、对比试验记录等纳入同一张图。第四步是“上线与监控”,在流程图中设定推理服务接口、版本控制、灰度发布策略、性能监控阈值、告警逻辑以及自愈方案。第五步是“迭代与回滚”,记录每一次迭代的原因、结果与后续计划;当某个特征、某个超参数组合导致性能下降时,流程图应提供快速回溯路径,帮助团队快速定位并回退到稳定版本。
在实际落地时,流程图不仅是思路的可视化,更是工具链的一部分。一个优秀的“流程图XGBoost”工具应具备以下特征:自动从数据描述生成初步的流程草图;在每个流程节点附带可执行的参数模板和检查清单;支持团队协作,版本化并能对比两版流程在相同数据集上的结果差异;提供与代码、实验记录、数据字典的双向链接,确保从图到代码、从代码到图的一致性。
工具应支持将流程图转化为可执行的脚本或模板,例如将数据清洗、特征工程、模型训练步骤导出为可复现的Notebook或Python脚本;也可以将评估与监控指标以仪表盘形式实时展现,帮助运维和产品方在生产阶段保持对模型行为的清晰认知。
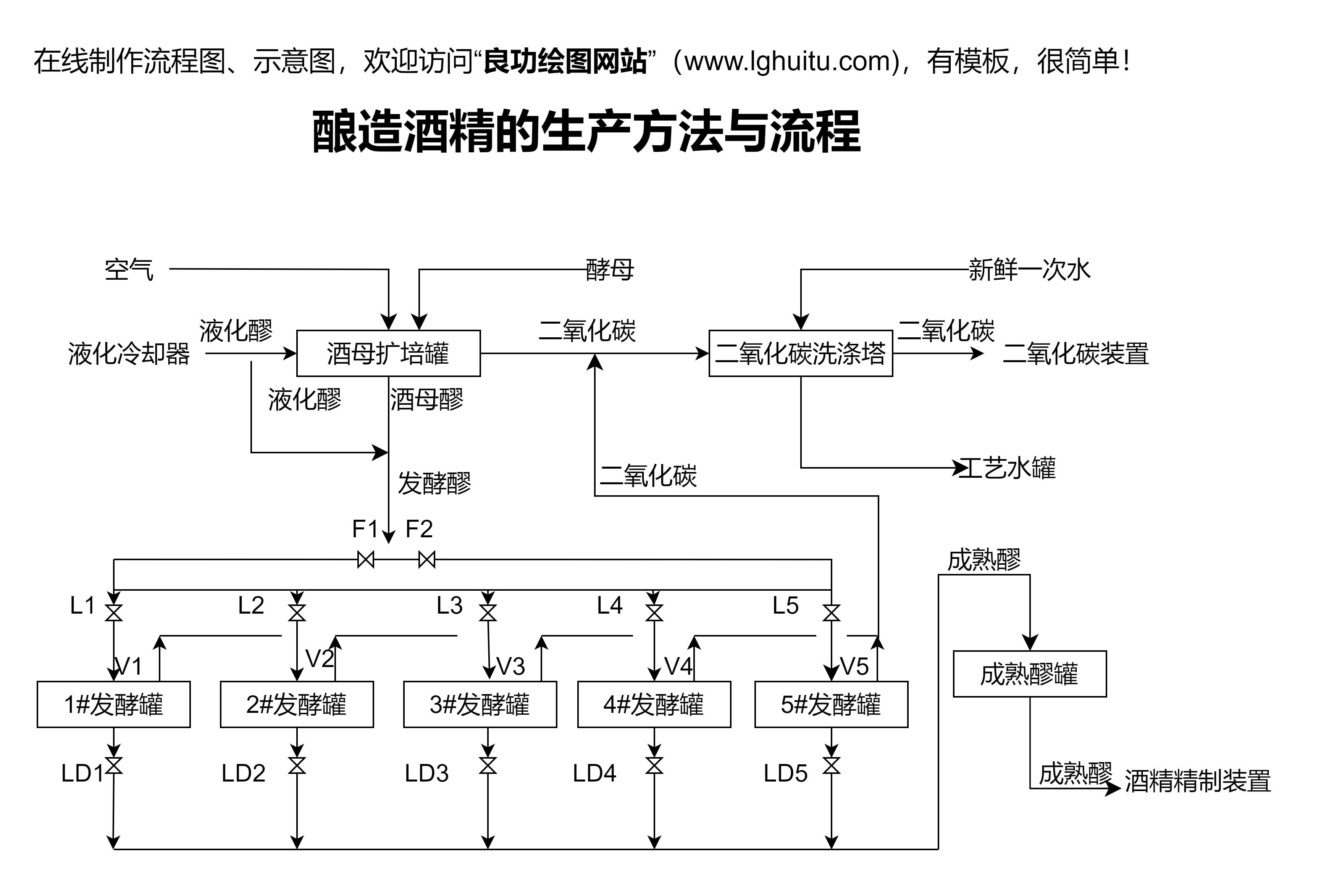
举一个典型的行业案例来说明流程图驱动的价值。假设在金融风控领域,你需要基于客户交易行为构建欺诈识别模型。通过流程图把数据输入、特征工程、样本不平衡处理、模型训练、早停策略、评估指标(如AUC、FPR、FNR)、特征重要性与SHAP分析、上线发布、日常监控、以及异常告警等逐一可视化,你可以确保团队各角色对风控阈值、排除条件和应急处置都有清晰的理解和预案。
在模型上线后,流程图还可以被用来定期自检:新数据到来时,是否触发重新训练?是否需要重新评估特征相关性?如果有特征漂移,流程图中的监控分支会提示进行重新标定、修正或回滚。正是这份可视化的“运营手册”,让复杂的模型治理变得透明、可控,确保风控系统的稳定性与合规性。
流程图的另一个核心价值是“协作加速”。在跨团队协作中,往往存在信息孤岛:数据科学家可能偏重模型性能,数据工程师关注数仓与数据质量,业务分析师关注业务含义与风控阈值,产品经理关注上线时机与用户体验。通过同一个流程图,大家可以在同一视角下对齐目标、分享假设、评估风险、记录决策理由。
对于初创团队而言,流程图是最短路径的知识沉淀;对于成熟企业,它则成为持续改进的蓝本与合规审计的证据。
最后回到“落地与可持续性”的问题。任何一张漂亮的流程图,若缺乏持续维护,都会很快失去价值。实现可持续的流程图实践,需要在组织内部建立如下机制:版本化的图谱存储与变更管理、统一的术语表和度量口径、定期的流程图回顾与培训、以及与业务KPI的对齐。
只有当流程图成为日常工作的一部分,XGBoost的强大才能被充分释放:模型不仅能在实验室里展现高分,还能在生产中稳定、透明地服务业务。流程图XGBoost,正在把“复杂性可控、协作可复制、治理可验证”的三重目标,变成可持续的现实。若你愿意让这套可视化方法落地,我们有灵活的方案与工具,帮助你的团队在短时间内把路线图变成可执行的生产力。