在机器学习与统计学领域,混淆矩阵(ConfusionMatrix)是评估分类模型性能的"黄金标准"。它以矩阵形式直观展示预测结果与真实标签的对应关系,包含真正例(TP)、假正例(FP)、真反例(TN)、假反例(FN)四个核心指标。相比单一准确率,混淆矩阵能揭示模型在类别不平衡、误判代价差异等场景下的真实表现。
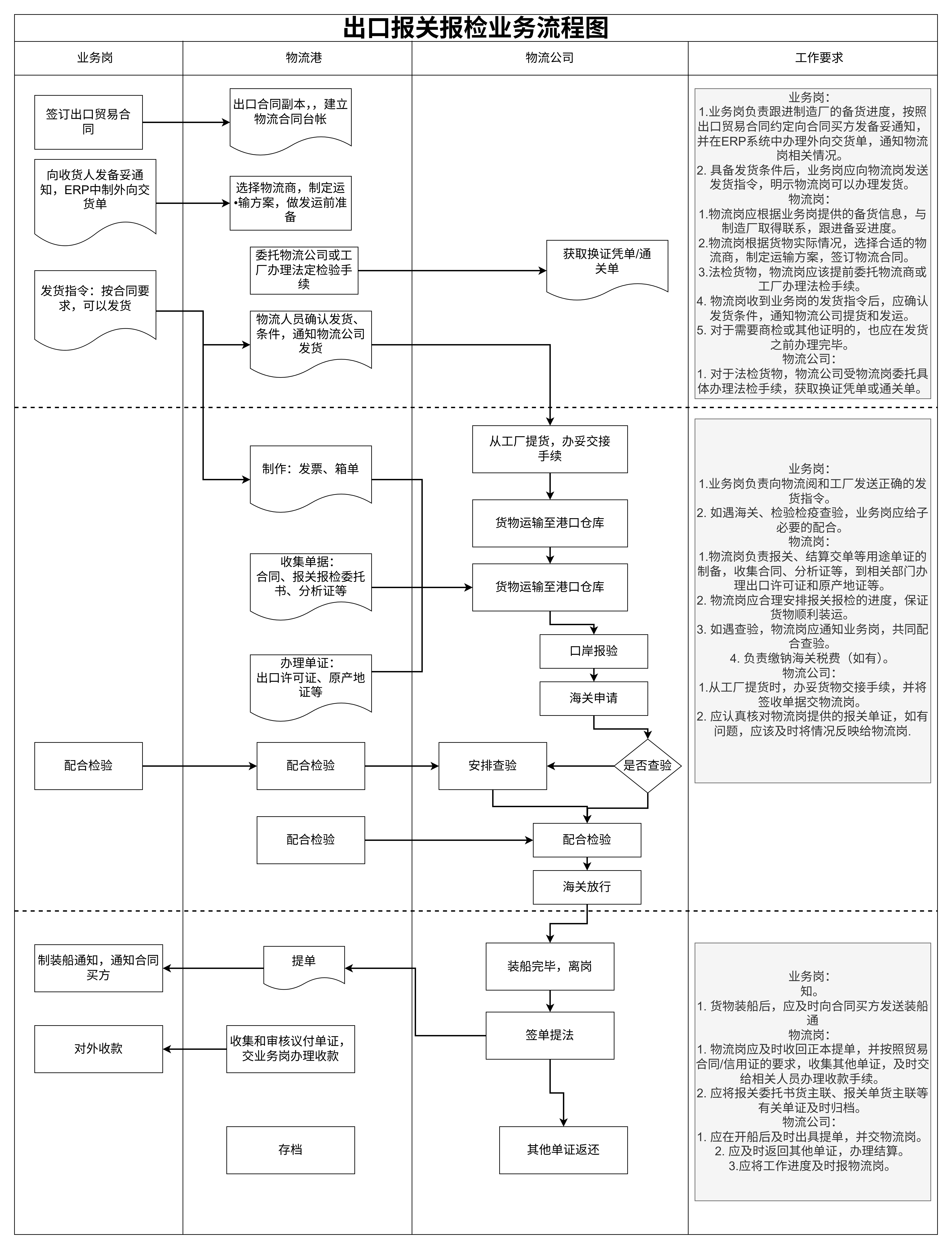
例如在医学诊断中,将恶性肿瘤误判为良性的代价(FN)远高于反向误判(FP),此时混淆矩阵的分析价值尤为突出。
Python生态工具链Matplotlib+Seaborn组合:通过heatmap函数实现基础热力图,支持自定义颜色映射与注释格式Scikit-learn内置函数:plot_confusion_matrix提供标准化输出,但定制化程度有限Plotly交互式图表:支持动态悬停显示数值,适合论文补充材料或在线展示专业可视化软件Tableau:通过拖拽操作快速生成矩阵,支持多维度数据钻取RAWGraphs:开源工具提供模板化设计,适合非编程用户LaTeX集成方案使用pgfplots宏包绘制出版级矩阵,确保矢量图清晰度与期刊格式要求完美契合

fromsklearn.metricsimportconfusion_matriximportseabornassnscm=confusion_matrix(y_true,y_pred)sns.heatmap(cm,annot=True,fmt='d',cmap='Blues')plt.xlabel('Predicted')plt.ylabel('Actual')

未标准化数值导致类别不平衡的视觉误导使用高对比度色系造成色觉障碍读者阅读困难忽略坐标轴标签旋转导致的文字重叠
颜色编码的认知心理学采用渐变色系时,应遵循"冷色调表正确,暖色调表错误"的通用约定。推荐使用:Viridis/Cividis色盲友好色板双色渐变(如蓝-白-红)突出对比避免使用超过3个主色造成视觉混乱多维度信息嵌套技巧在单元格内叠加分类正确率百分比使用气泡图大小表示样本量差异添加误差条显示交叉验证波动范围动态交互增强叙事性通过Altair或Plotly实现:鼠标悬停显示详细统计量点击过滤特定类别子矩阵动画展示模型迭代过程中的性能演变
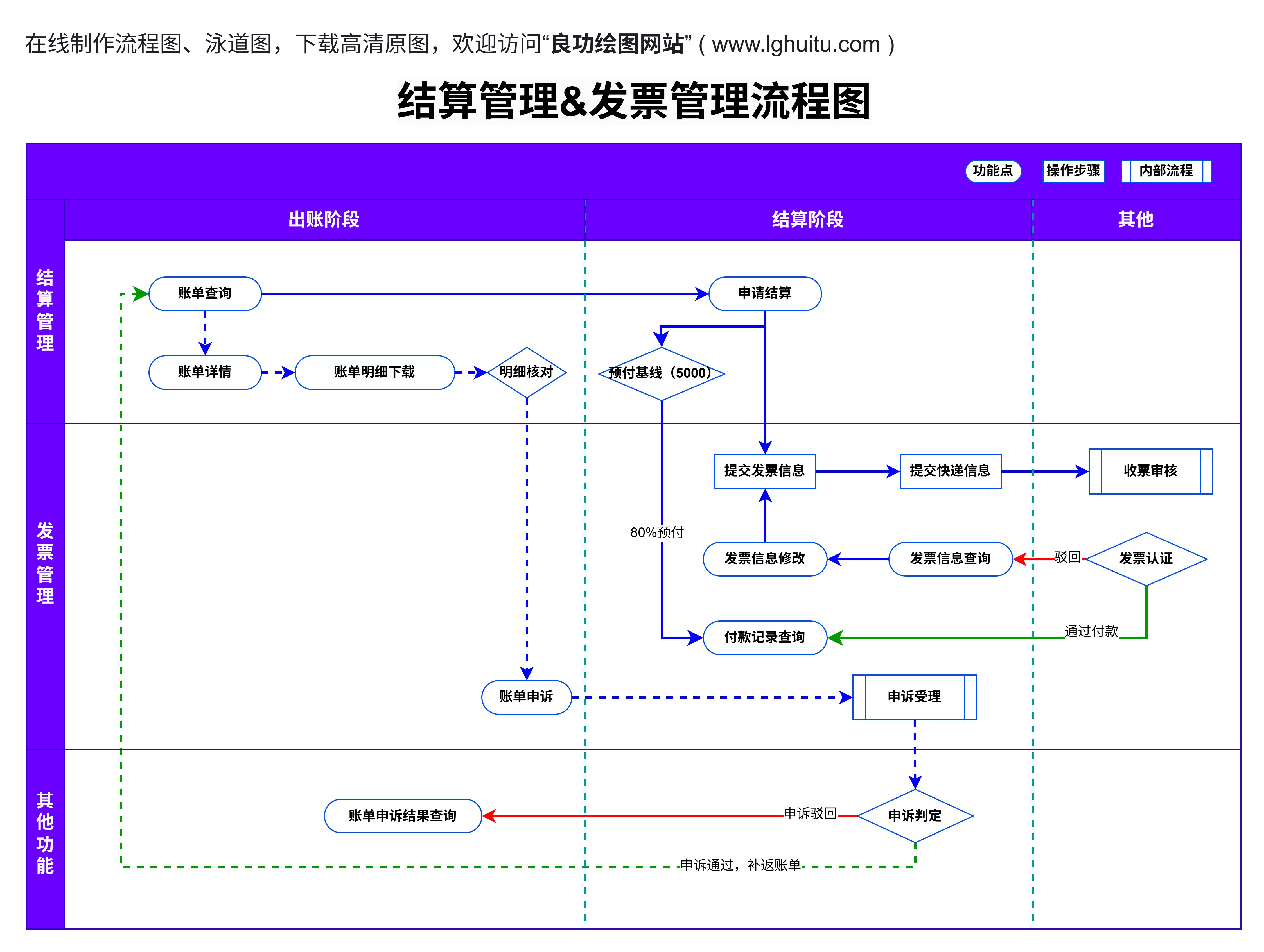
IEEE/Springer格式规范字体:TimesNewRoman8pt(坐标轴),10pt(标题)线宽:0.5pt的细边框分辨率:至少600dpi的TIFF或PDF格式可复现性设计在图表脚注标注代码版本(如Matplotlib3.7.1)使用CSS4命名色值确保色彩一致性提供可编辑的矢量图源文件跨文化传播考量为中文期刊添加双语标签(主标签中文,括号内英文)时区敏感场景使用24小时制时间戳宗教敏感地区避免使用十字交叉形图示
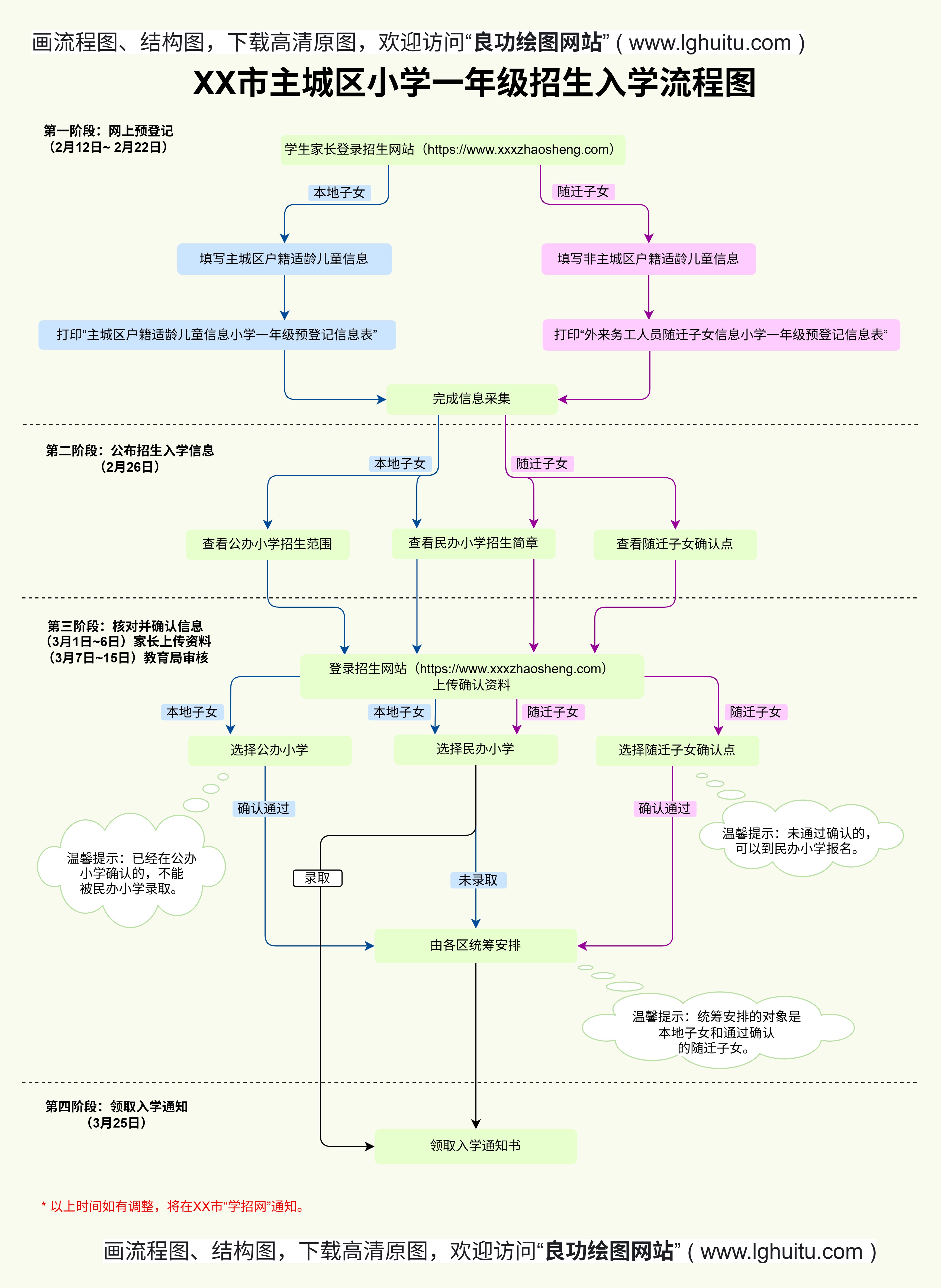
分析2022年NatureMedicine某篇论文中的混淆矩阵:
采用3D堆叠条形图展示多时间点预测对角线使用金属质感渐变突出正确分类辅助线连接混淆路径揭示典型误判模式右下角嵌入微型ROC曲线作为性能参照
通过本文的深度解析,研究者不仅能掌握混淆矩阵的绘制技术,更能理解其背后的视觉传达逻辑。在学术竞争日益激烈的今天,一个兼具严谨性与表现力的混淆矩阵,往往能成为论文评审中的"视觉加分项"。建议读者立即使用文中的代码模板,结合自身研究数据进行实践,开启数据可视化能力的新维度。
