随着人工智能技术的快速发展,AI已经成为了改变各行各业的重要力量。无论是自动驾驶、语音助手,还是智能客服、图像识别,AI在我们的日常生活中无处不在。而这一切的背后,离不开一个复杂且充满挑战的制作流程。从概念的萌发,到模型的训练,再到实际的应用,AI的制作过程充满了许多创新与技术突破。

在AI的制作流程中,数据是最为重要的原料。可以说,AI的“智慧”来源于大量的数据积累。数据采集的过程通常是AI开发的第一步,涉及到从各种来源收集和整理大量的数据。这些数据可以是文本、图片、音频、视频,甚至是传感器数据等。比如,在开发语音助手时,开发团队需要大量的语音数据来训练模型,使得AI可以理解并回应用户的请求;在图像识别领域,则需要成千上万的标注图片来帮助AI“识别”不同的物体。

数据的质量直接影响到AI模型的效果,因此数据采集过程不仅仅是数量上的收集,更多的是确保数据的准确性和多样性。为了构建一个高效、智能的AI系统,开发者通常会花费大量的时间对数据进行清洗、去噪、标注等预处理工作。这个阶段的目标是确保AI模型在训练时能够接触到尽可能多样化和有代表性的数据,从而提高模型的泛化能力。
数据准备好之后,下一步就是为AI选择合适的“模型”。AI模型是人工智能系统的核心部分,决定了AI系统的智能程度和实际应用效果。常见的AI模型包括深度学习模型、决策树、支持向量机(SVM)、K近邻算法(KNN)等。
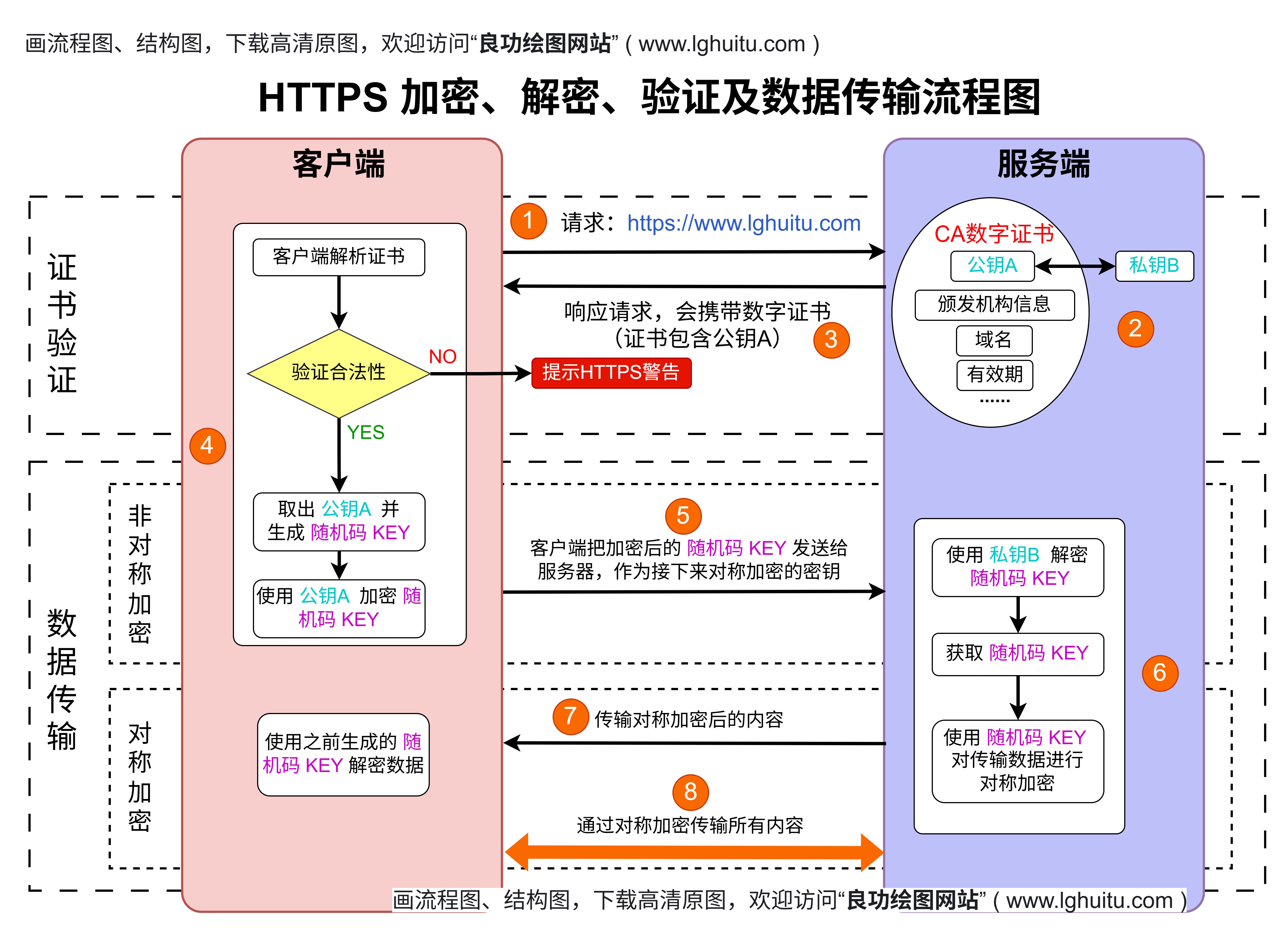
在这一阶段,开发团队会根据具体的应用场景和数据特征选择最适合的算法。例如,在自然语言处理领域,常用的模型有BERT、GPT等,它们能够理解和生成自然语言;在图像识别领域,常见的模型则是卷积神经网络(CNN),它能通过模拟人脑的神经网络结构识别图像中的不同特征。
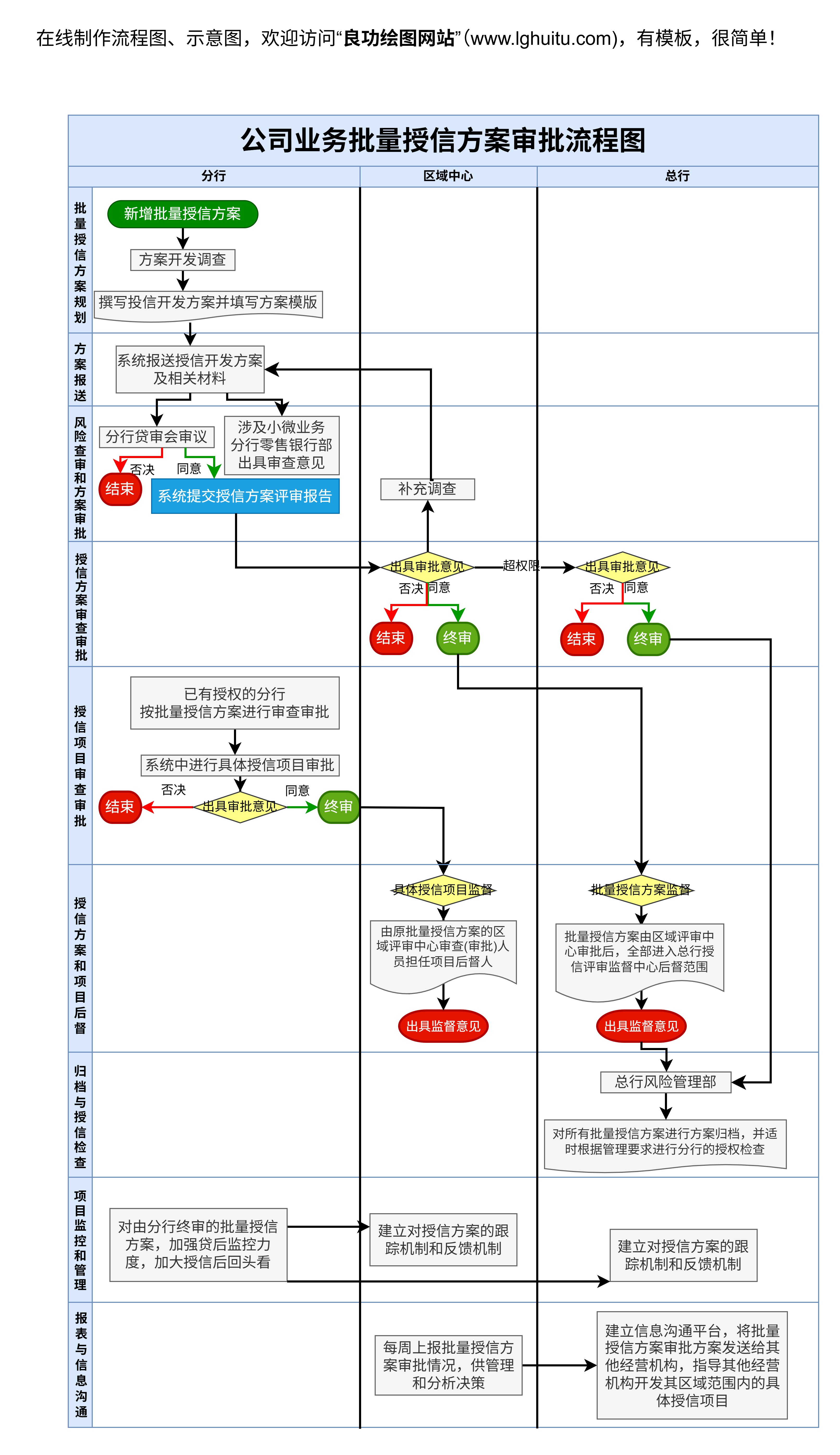
选择合适的模型,不仅是对技术的考验,也是对应用场景的深刻理解。不同的AI模型适用于不同的任务,开发者需要根据实际需求对模型进行调整和优化。在这个阶段,模型的初步设计与算法选择至关重要,它直接关系到AI的最终效果。

当模型设计好后,接下来便是最为关键的训练环节。AI模型的“智慧”来自于训练过程中不断调整的权重和参数,这个过程需要借助大量的数据和计算资源。
训练AI模型的过程通常是通过反向传播算法来调整模型参数,使得模型的输出逐渐接近实际的结果。例如,在图像识别中,AI模型通过不断与真实的标签数据进行对比,学习如何准确地识别图像中的对象。这一过程中,开发团队需要使用高效的优化算法,如梯度下降法,来帮助模型尽快收敛并达到最佳状态。
训练的过程是非常耗时且资源密集的,尤其是在深度学习领域。随着数据量和模型复杂度的增加,训练的时间和计算资源需求也会大幅度增加。为了加快训练速度,许多开发团队选择借助高性能的硬件设施,如GPU和TPU,来加速模型训练过程。训练过程中还需要对模型进行调优,调整学习率、正则化方法等超参数,以防止过拟合或欠拟合,确保模型的稳定性和准确性。
经过大量训练后的AI模型,还需要经过严格的评估与验证。这一步骤的目的是验证模型的效果,确保它在实际应用中能够表现出理想的性能。
评估AI模型的常见方法有交叉验证、混淆矩阵、ROC曲线等。开发团队会将数据集划分为训练集和测试集,通过测试集来评估模型的准确性、精度、召回率等指标。这一过程帮助开发团队了解模型的实际能力,并及时发现可能存在的问题。
例如,在自动驾驶领域,开发团队会通过大量的真实场景数据来测试模型的反应能力,确保它能够在不同环境下做出正确的判断。在语音助手应用中,开发者则需要通过实际用户的语音数据,评估模型是否能够准确理解不同口音、语速和语境下的语言表达。

评估阶段的重要性不可忽视,因为即使一个模型在训练时表现得非常优秀,也不代表它在实际环境中同样可靠。只有通过严格的验证,才能确保AI系统的稳定性和安全性。
当AI模型经过评估并确认能够达到预期效果后,接下来便是部署阶段。部署的过程是将模型应用到实际环境中,让AI系统在现实中发挥作用。
部署时,开发团队通常会选择适合的计算平台,如云计算平台、边缘计算设备等。根据不同的应用场景,AI系统可能会被集成到移动设备、智能硬件、服务器等设备中,以便为用户提供服务。在部署过程中,团队还需要考虑到系统的可扩展性、稳定性以及安全性,确保AI应用能够在各种环境下长期稳定运行。
部署并不是终点。在AI模型部署后,团队还需要不断进行监控与维护。AI模型会随着时间的推移和环境的变化而出现性能下降或错误,因此需要持续进行更新与优化。通过不断监控数据反馈,开发者可以及时发现问题并进行调整,确保AI系统始终保持高效和可靠。
总结:从构想到实现,AI的制作过程是一个复杂而精细的工程。从数据采集到模型设计,再到训练、评估和部署,每一步都需要精湛的技术和细致的工作。AI的成功不仅仅是技术的突破,更是团队协作与创新的结晶。在未来,随着技术的进步与创新,AI将会继续引领行业发展,改变我们的生活方式。