在生物医学研究领域,单细胞分析技术的兴起带来了前所未有的突破。随着科学技术的不断发展,传统的基因组学和蛋白质组学研究已逐渐无法满足精细化分析的需求。传统方法常常将组织样本作为一个整体进行研究,这样往往无法揭示不同细胞之间的微小差异。单细胞数据分析则为解决这一问题提供了强有力的技术支持,使得研究人员可以在单一细胞水平上进行更精细的研究,从而揭示出许多之前难以察觉的细胞行为、基因表达和生物学特征。
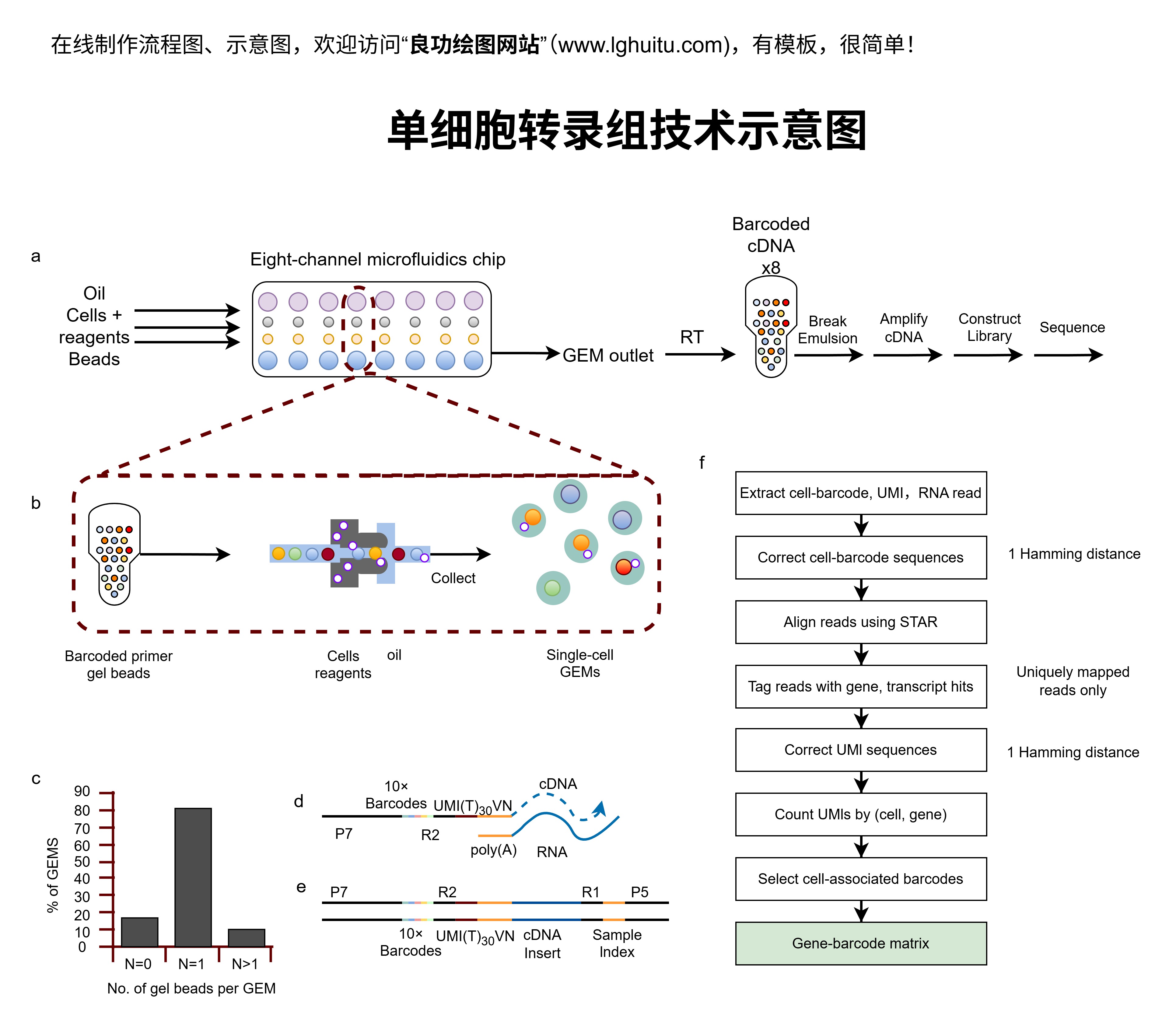
单细胞数据分析的关键在于获取单细胞的原始数据。通常,单细胞数据来源于RNA-seq、ATAC-seq、CITE-seq等技术,这些技术能够帮助研究人员从基因表达、染色质开放状态到蛋白质层面收集各种细胞信息。在获取数据的过程中,研究者通常会借助流式细胞仪、微流控芯片等先进设备对细胞进行分离,并对每一个细胞进行高通量的测序。
接下来是数据预处理的阶段。在获取到单细胞数据后,由于数据量庞大且包含大量噪声,数据的质量控制和清洗显得尤为重要。首先要剔除低质量细胞,去除异常的测序结果。例如,在RNA-seq数据中,低质量细胞通常表现为较低的基因表达量或者不合理的基因表达模式,因此需要采用合适的算法去除这些噪声细胞。常见的数据清洗方法包括基于质量的过滤、数据标准化以及去除空白值等。
数据预处理完成后,进入了数据的降维和特征提取阶段。单细胞数据通常包含数千至数万个基因的信息,这些信息的高维特性使得数据难以直接分析。因此,研究人员常常使用PCA(主成分分析)、t-SNE(t分布随机邻域嵌入)或者UMAP(统一流形逼近与投影)等降维技术,将高维数据转换为低维空间,以便更好地展示细胞之间的差异性。特征提取技术能够帮助研究人员挖掘数据中最具代表性的特征,这些特征常常能为后续的分析提供重要线索。
单细胞数据分析的下一步是对细胞进行分类和聚类。由于单细胞数据的复杂性,细胞的异质性非常强,不同类型的细胞在表达谱上存在显著差异。聚类分析能够帮助研究人员将相似的细胞归为一类,从而揭示细胞群体的多样性。常见的聚类方法包括基于图论的k-means、DBSCAN等算法,它们通过计算细胞之间的相似度或距离,成功地将细胞进行分组。这一过程对于揭示细胞功能的异质性、发现新的细胞亚群以及研究不同细胞类型之间的相互关系具有重要意义。
单细胞数据分析的下一个关键环节是细胞轨迹推断与动态分析。细胞轨迹推断旨在揭示细胞如何从一种状态转变到另一种状态,特别是在发育、分化或疾病进程中,细胞的转变往往伴随着复杂的生物学机制。通过单细胞RNA-seq数据,研究人员可以利用轨迹推断方法,例如Monocle、Slingshot等算法,构建细胞在不同状态下的轨迹图谱,进而探索细胞命运决策的关键节点。通过这些分析,科研人员不仅能更好地理解细胞的发育过程,还能对疾病发生过程中的细胞行为做出深入解析。
基因共表达网络的构建也是单细胞数据分析中的重要任务。单细胞基因表达数据的丰富性使得通过共表达分析来发现基因之间的潜在关系成为可能。研究人员可以通过构建基因共表达网络,识别出在特定细胞群体或疾病状态下表达密切相关的基因模块。这不仅有助于揭示基因调控网络的复杂性,还能为靶向药物的开发提供重要线索。
单细胞数据分析还能够帮助科研人员进行生物标志物的发现。在疾病的早期诊断、预后判断以及药物反应预测中,生物标志物的作用至关重要。通过单细胞数据,研究人员能够发现与特定疾病相关的基因表达模式,识别出潜在的生物标志物。这些标志物不仅有助于疾病的早期诊断,还能在治疗方案的制定过程中发挥重要作用。
单细胞数据分析的结果不仅限于基础科研,还可以应用于临床实践。随着精准医学的发展,单细胞技术能够为临床医生提供个性化的治疗方案。通过深入分析患者的单细胞数据,医生可以更好地理解疾病的分子机制,从而选择最合适的治疗策略,提高治疗效果和患者的生存率。
单细胞数据分析的流程涵盖了从数据获取、预处理到降维、聚类、轨迹推断等多个步骤,涉及生物信息学、统计学、机器学习等多学科的深度交叉。随着单细胞分析技术的不断进步,这一流程将在精准医学、疾病研究等领域发挥越来越重要的作用。对于科研人员而言,掌握单细胞数据分析的技巧无疑将为他们打开新的研究视野,推动生物医学研究的深入发展。