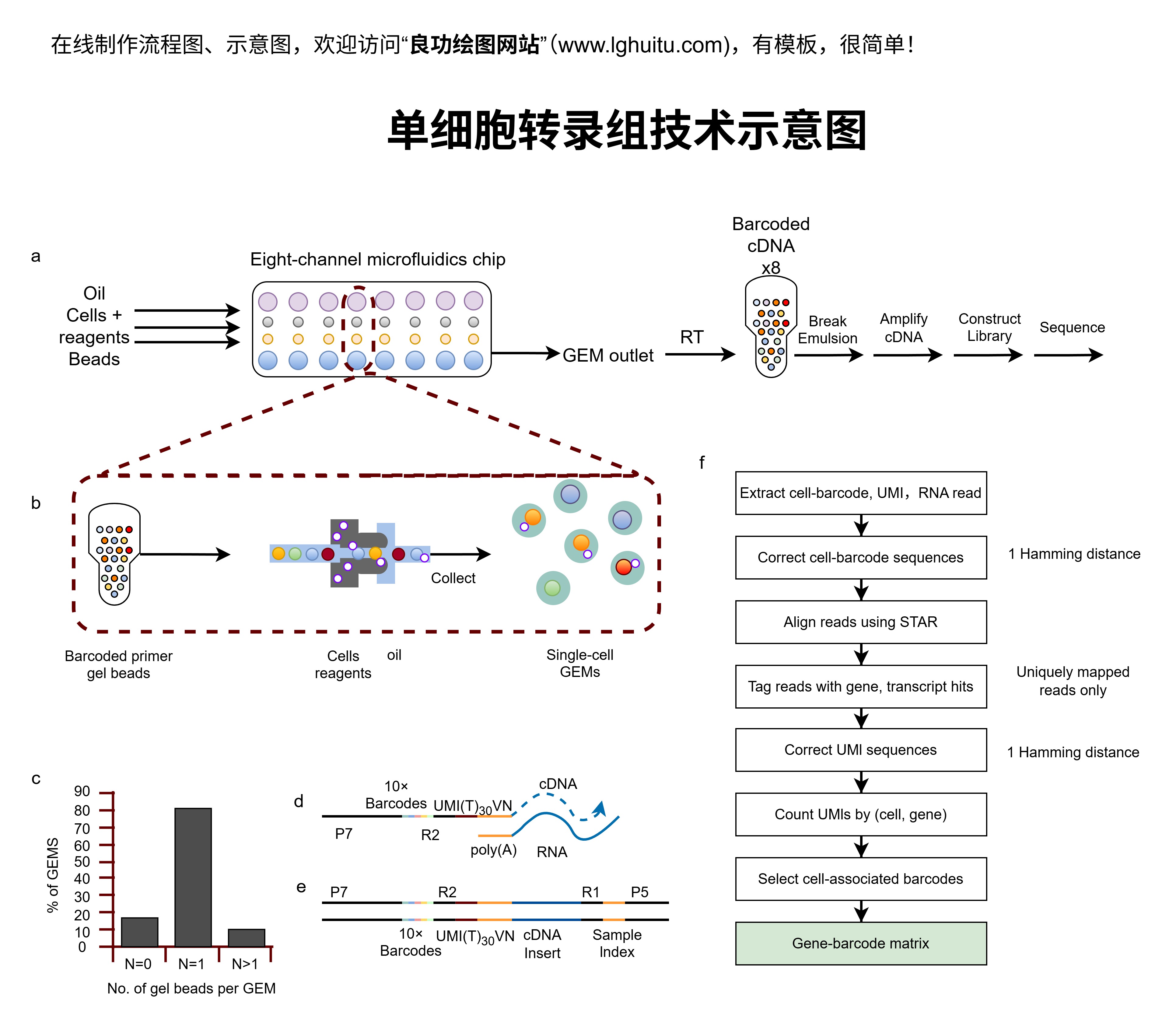
单细胞转录组(scRNA-seq)技术是近年来在生命科学领域中备受瞩目的创新工具。相比传统的转录组技术,单细胞转录组能够对个体细胞进行单独分析,为我们揭示了细胞异质性的重要信息。这项技术不仅能深入探索细胞的基因表达谱,还能提供关于细胞状态、功能和谱系关系的详细视图。要确保通过scRNA-seq获得的数据准确无误,数据质控便显得尤为重要。
单细胞转录组数据质控是指在数据分析过程中对原始数据质量进行评估和筛选的过程。这一环节能够有效地去除低质量的细胞和实验偏差,确保后续分析的准确性与可靠性。如果忽视这一环节,可能会导致错误的生物学结论,甚至影响科研成果的发表。
在单细胞转录组数据质控的实施过程中,首先需要对数据进行初步的过滤。这一步的核心目标是剔除那些质量不佳的细胞或数据。低质量的细胞可能由于样本处理不当或仪器性能不稳定,导致表达谱异常,或者在技术层面产生误差。通过设置过滤标准,比如基因数目、总的转录本数量及线粒体基因表达比例等,可以有效识别并剔除这些低质量样本。
数据质控的另一项关键任务是评估批次效应。单细胞转录组数据的生成通常需要多个样本进行多次测序,这就可能导致不同实验批次间的系统性误差。这些批次效应可能源于样本处理、测序平台、试剂批次等因素。为此,研究人员可以采用批次效应校正方法,如ComBat算法,来减少这些技术性偏差对数据分析的影响。通过这一手段,可以有效提高数据的一致性,确保实验结果具有较高的可重复性。
在数据预处理和质控完成后,下一步则是对数据的质量进行定量化评估。质量控制的主要目标之一是确保每个细胞的基因表达量足够准确,并且能反映出细胞的真实状态。研究人员可以使用多种统计方法来进行评估,例如,计算每个细胞的转录本数目分布,或者使用PCA等降维技术进行整体数据的可视化。通过这些方法,不仅可以有效检测出数据中的异常值,还能够帮助科研人员更好地理解数据的整体结构。
除了基础的质控步骤,单细胞转录组数据质控还包括对细胞群体间异质性的识别。由于单细胞转录组技术可以揭示单个细胞层级的基因表达特征,不同细胞群体之间的表达差异往往成为研究的焦点。因此,数据质控中需要注意的一个重要环节是群体分类和亚群体的细致划分。通过细胞簇群分析,研究人员能够识别出不同生物学状态下的细胞群体,并通过调整质控标准来确保每个亚群体的表达谱都能够得到准确的反映。
随着大数据技术的迅猛发展,单细胞转录组数据也面临着庞大计算量和复杂数据处理的挑战。传统的数据质控方法已无法应对海量数据的处理需求,因此,越来越多的自动化质控平台应运而生。这些平台通过智能化的算法和高效的数据处理技术,能够实时检测数据质量,并自动生成质量控制报告。科研人员可以通过这些平台对数据进行批量处理,减少人工干预,提高实验效率。
现代数据质控不仅仅依赖于细胞水平的过滤和检测,也需要结合样本的生物学特性进行分析。例如,对于不同来源的细胞样本,可能需要根据其特定的基因表达特征来定制质控方案。针对不同的科研目的,数据质控的标准也应具有灵活性和针对性。针对某些特定的疾病研究或免疫细胞亚群体分析,科研人员可能需要特别关注某些基因或标志物的表达情况。
随着单细胞转录组技术的不断发展,其应用场景也日趋广泛。从癌症研究到神经科学,从免疫学到发育生物学,单细胞转录组为我们带来了前所未有的研究视角。数据质量的保证始终是科学研究的基石。只有在经过严格质控的数据基础上,科研人员才能从复杂的基因表达信息中提炼出具有生物学意义的结论,推动生命科学的进步。
因此,单细胞转录组数据质控不仅是数据分析的第一步,更是保障研究成果科学性和可靠性的关键环节。在未来,随着技术的进一步发展,数据质控将更加精细化、智能化,助力科研人员在基因组学研究中不断取得突破,为人类健康做出更多贡献。